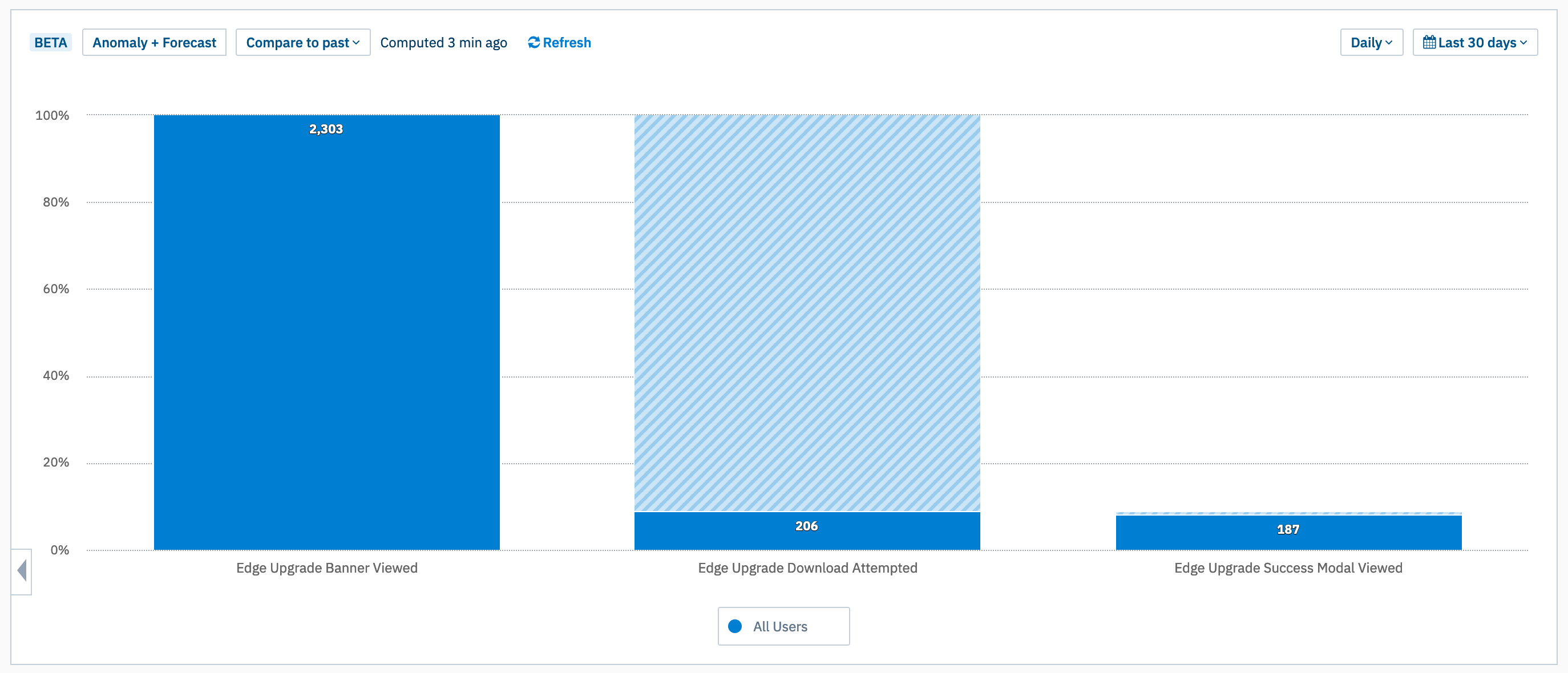
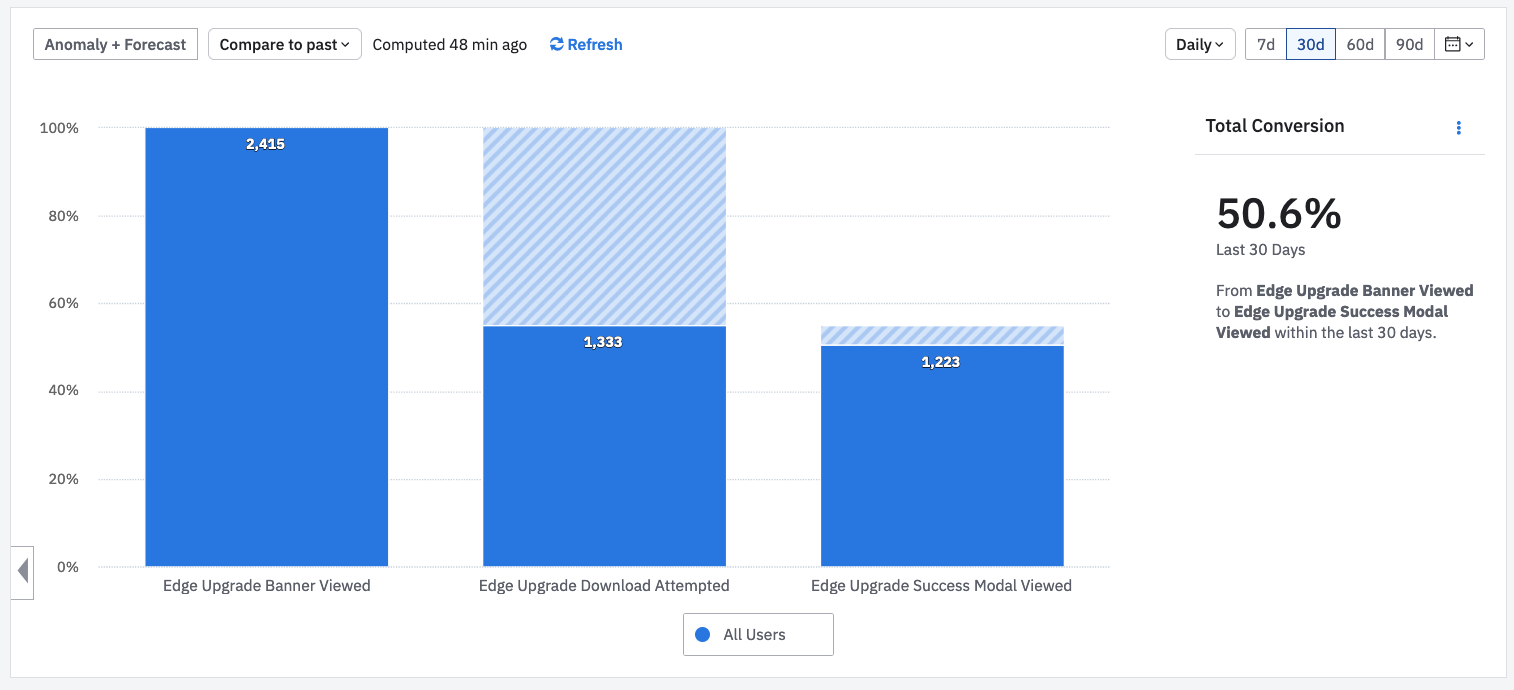
I’ve been working at Culture Amp for over 8 years – 4 times longer than any other place I’ve worked. Clearly something here is working well for me.
When Didier Elzinga recently stepped down as CEO, it made me realise I want to share parts of my story here and why it’s been good, because it ties into the “Culture First” idea that’s the driving force behind the company he, Rod, Doug and Jon founded.
For me it’s really important to be working for an organisation with a positive mission. Culture Amp’s mission fits this: “to create a better world of work”. Full time workers spend a third of our time at our jobs – improving work is a way of improving lives. Culture Amp makes a software product to help companies be good to their people, to be “Culture First”. The idea isn’t vapid: there’s a firm belief, backed by research, that being good to your people is a path to high performance, positive impact, and business success.
The part of this mission that has resonated with me the most is not just making the product, but proving to the world that the idea is real. Culture Amp wants to be the example that proves the theory.
Here’s what “Culture First” has looked like for me in my 8 years here.
“We borrow our time at work from people and things much more important to us than the work”.
Didier Elzinga
Culture First: a beautiful reciprocity
There’s been a beautiful reciprocity in my experience working for Culture Amp. The company has been good for me personally, and I know I’ve provided my share of value to the growth of the business on its path from 150 employees to 900, and to over 10 times the annual recurring revenue.
Here are some concrete examples of what these mutually beneficial exchanges look like:
Respect in the interview process: The technical exercise was interesting, the people who interviewed me were friendly, curious, and were clearly great engineers. I am not naturally a strong negotiator, and I had given a conservative salary range when asked about my expectations. But they made me an offer above the salary range I’d asked, offering what they thought I was worth, even when I wasn’t confident to ask that for myself. I felt respected. That feeling of respect is why I said yes to their offer and was excited to join.
Regular performance and compensation reviews: 3 months after I joined, I was still happy with the extra pay compared to my last job. I had my first performance review, and they decided I was performing better than the level they had assigned me in my interview, and gave me a pay rise. I didn’t even ask for it. Since then there’s been a regular rhythm and trust – I know there will be reviews every 6 months, that they evaluate my performance against their levels, that they work hard to be fair and reduce bias, and that the salary bands are calibrated against market data. Pay negotiations don’t come naturally for me. The fact that I work somewhere with a consistent and fair process has made me feel confident I’m not being taken for granted, and has been a big part of my loyalty – and it motivates me to increase my impact, trusting it will be rewarded. Because it has been.
Supporting my tech community involvement: They encouraged me to use my interest in public speaking to submit talks to tech conferences. They allowed me to do some preparation on work time. And in return, more potential engineers heard about Culture Amp and at least a few ended up joining us and providing long term value to the company – without needing to pay commissions to recruiters! And I got to become a more visible member of the tech community and use my gifts there.
Going remote before Covid: When I interviewed in 2017, I was living in Melbourne but knew I would be moving to Perth. They said they would be open to remote work if I did my first few months in Melbourne – they had a small handful of remote engineers already. A few months in when I asked about the timing of the move – they put the question back to me using one of their values: “trust people to own decisions“. My manager asked me to think through the impact of being remote, and what would be required for it to be successful, and make a decision accordingly. I did, and it went well enough that I kept thriving. When the team lead role opened up, I wanted to try, but no one else was a remote team lead back then. They still encouraged me to apply. They trusted I could pull it off, and I became one of the first two remote product team leads in 2018. And this benefited them – two years later when Covid hit I was able to share what I knew and help the company quickly adapt to effective remote work. They took a chance on my leadership looking different, and with that experience I could then help them navigate one of the most abrupt work culture transitions of our time.
Management training: This was my first job where I got to lead a team. Culture Amp has been the ideal place to learn. I had great managers myself who I could learn from. (Thanks Kevin, Jordan and Eric!) They invested in manager training with Lifelabs right at the start of my journey. They encouraged using our own product to ensure we were getting feedback. We were given help to reduce our bias in hiring and performance decisions. Our People and Experience team helped me navigate both happy conversations and tough conversations. There was so much support available. I’ve been able to ask questions on Slack – from team trust dynamics to goal setting – and I’ve had replies from other team leads, from senior leaders, and even from people with PhDs in organisational psychology who specialise in those topics. It’s a phenomenal environment to learn to manage people. Because I’ve been equipped like this, I’ve been able to lead well. I’m proud to have seen plenty of my people promoted, and a few grow through a period of struggle and low impact and get back to a place where they’re thriving. And we’ve completed plenty of really high impact projects.
Parental leave: When my first child was born in 2018 Culture Amp offered 6 weeks paid parental leave, and dads were explicitly encouraged to take it. The company acknowledged the ways early parental leave can shift the ongoing balance of care between mums and dads, and lead to more equitable career outcomes for both parents. It also helps normalise a culture of employees putting their family first, which reduces bias against women who take their full parental leave entitlements. And of course, it gives you more time with your kids in those precious first few months, which you can’t put a price on. When my second child was born, the policy changed to 4 weeks for secondary carers, and 16 weeks for primary carers. (These days it’s 16 weeks for everyone.) Given my partner at the time was a stay-at-home mum, I applied for the secondary carer’s leave. But then, life turned out to be really hard. Having that second child was the start of prolonged sickness, mental health challenges, and an understanding of neurodiversity in our family. I needed to take a lot of time off to look after my family. I exhausted my parental leave, then my carer’s leave and annual leave. By this point my manager had been having conversations with HR and got approval for me to have the remaining 12 weeks of “primary” leave given the exceptional circumstances. They even offered to let me take it in a part time capacity to stretch it over the remainder of the year. This was an absolute lifeline. If I wasn’t offered it, I probably would have had to resign – the pressure at home was so huge. It took a few years for more support at home to be available, and for me to find a new and more sustainable “normal”. Getting through that time was incredibly difficult. The way my managers, senior leaders, and the HR team looked out for me, provided options, and trusted me even through a period of struggle and lower impact, earned them a huge degree of loyalty from me. They trusted me – and trusted in my future impact – and did what they could to help me through one of life’s toughest seasons. And in return, I’ve been able to give several more years back at a strong level of performance.
So you can see there has been a reciprocal trust and investment and benefit between me and the company.
Shared humanity
There’s another story of my time at Culture Amp that is far more human and can’t be quantified in growth rates for the company or career growth for me.
Early in my tenure someone new joined our team. They were a brilliantly sharp engineer who overlapped in a lot of the same technical interests and specialties as me, but whose ability to think about complex systems, both technical and social, allowed them to identify patterns others didn’t see. It was wonderful to watch their strategic thinking at work. I learned a lot from them and working with them was a highlight of my career.
They were also the first friend to openly talk to me about the experience of being autistic. We’d been working together for a few years, and my understanding of neurodiversity was pretty limited. I think when I noticed people struggling with sensory overwhelm in large group settings I would have put it down to an “extrovert / introvert” dynamic and not thought more about it.
Culture Amp has a company value “Have the courage to be vulnerable”, and one way of expressing that is sharing parts of your authentic identity at work. But doing so requires trust. That trust built up over a few years, and eventually there was enough for them to talk openly with me about being autistic.
It was a beautiful thing to have someone I respected so much, and who I counted as a friend not just a coworker, help me understand how their motivations at work play out, why many office environments are overwhelming, why restructures and team instability can be very destabilising, and why some software problems are really well suited to their brain, and others are not.
They’d take time to explain parts of their experience, like why you can struggle to focus on the task in work hours, only to struggle to stop in the evening – they explained the struggle isn’t the ability to focus, the struggle is the ability to regulate focus. And that includes struggling to stop even when hyper-focused at an inconvenient or unhealthy time.
Or they’d send links to articles like this that help reframe communication problems as an equal burden between someone neurotypical and someone neurodiverse1. Things like this helped me understand neurodiversity so much better, and removed any sense of stigma from it.
Just a couple of months after these conversations started, we had the first signs that my eldest son might be autistic. He was three, and his mum had interrupted a repetitive behaviour, and his response was an extreme meltdown. It started a conversation, and a family friend who is a school psychologist came and talked to us about it. After watching him play, she said we should definitely be seeking a diagnosis.
It was a big moment. Did my son have a disability? Would he grow up normal, or would this make everything different? I loved him and his quirks. I didn’t want to start seeing him differently. When I talked to friends about it – I’d well up with tears, I didn’t want the world to not appreciate him. I didn’t want to not appreciate him.
In that time, with all of the big questions that it brought up in me as a dad, the thing that gave me the most encouragement was my friend at work who was brilliant, kind, authentic, and generous. I had a picture of how beautiful an autistic life can be, and it gave me hope and reframed the diagnostic conversation for my son from one around a deficit to one around understanding him better. I’m incredibly grateful.
There’s also been that same reciprocity. Things like understanding the Interest Based Nervous System have made a huge difference to how I manage engineers, divide work, plan projects and line up growth opportunities. I’ve been a more effective manager, and it’s also helped me. My friend encouraged me that, with or without a diagnosis, if the strategies help, I can learn from them.
Someone at work also started a Slack channel for parents of neurodiverse kids. I literally cried when I found it. Parenting neurodiverse kids well as they’re adapting to a world that isn’t always friendly to their brain is no easy task. Realising I wasn’t alone, and that workmates I’d collaborated with had the same struggles was such a big moment of feeling seen and understood. They were here, sharing stories, providing mutual support.
My understanding of myself, my friend at work, my children, autistic people – and humans in general! – was made so much richer, because there was a “courage to be vulnerable” moment where someone opened up and shared so openly with me what their experience of being neurodiverse was like.
The value of Culture First
And here-in lies my point in writing this blog post. Culture Amp has tried to model a culture first approach and show other companies that it’s a good way to do business. And in my story – the ways the company has supported me has seen a return on investment – I’ve been more engaged and higher performing.
But it’s more than that transaction – some of the value created isn’t captured by the business. In my faith there’s this idea that “you shall not reap all the way to the edges of your field” – that you shouldn’t capture all of the value, and that it’s good if some of it is left for the community.
A culture first approach to business makes sense through an economic lens – more than enough of the value you invest in your people is returned to the business – it’s a smart strategy. But there’s a whole world of value that isn’t captured by the business, but enriches the lives of your employees, and their families, and our communities. It might not show up in your company performance dashboards, but this is the impact I most care about.
And I suspect it’s the impact Didier most cared about when he, Doug, Rod and Jon founded the company. For having the courage to start something and try to do it “Culture First” – and for the impact it’s had on me and my family and my community – I’m grateful.
—
- This was fascinating – in one study participants played the game “Telephone” – where each person passes a message down the line and you see how different it is at the end – with autistic groups, with non-autistic groups, and with mixed groups. You’d think that because part of an autism diagnosis is having communication deficits that the autistic group performs poorly. It’s actually the mixed group that suffers. ↩︎